
IBM a présenté une nouvelle puce d’IA analogique qui imiterait le fonctionnement du cerveau humain et qui peut effectuer des calculs rapides et économes en énergie pour l’intelligence artificielle. La puce contient 64 cœurs de calcul analogiques en mémoire qui sont reliés par un réseau de communication sur la puce. Elle utilise aussi des convertisseurs analogique-numérique et des unités de traitement numérique pour réaliser des fonctions d’activation neuronale et des opérations de mise à l’échelle. La puce pourrait remplacer les puces numériques actuelles qui sont utilisées pour les applications d’IA dans les ordinateurs et les smartphones.
IBM a dévoilé un nouveau prototype de puce d’IA analogique qui fonctionnerait comme un cerveau humain et qui peut réaliser des tâches complexes de réseaux neuronaux profonds (DNN). La puce est conçue pour rendre l’intelligence artificielle plus efficace et moins gourmande en batterie pour les ordinateurs et les smartphones. La puce est composée de 64 cœurs de calcul analogiques en mémoire qui sont interconnectés par un réseau de communication sur la puce.
Chaque cœur dispose d’un convertisseur analogique-numérique qui permet de passer du monde analogique au monde numérique. Chaque cœur dispose aussi d’une unité de traitement numérique légère qui exécute des fonctions d’activation neuronale simples et des opérations de mise à l’échelle. Ces fonctions sont nécessaires pour les couches convolutives et les unités de mémoire à long terme des réseaux neuronaux. Une unité de traitement numérique globale est située au centre de la puce et réalise des opérations plus complexes qui sont requises pour certains types de réseaux neuronaux.

La puce prototype d’IBM pourrait être une alternative aux puces numériques actuelles qui sont utilisées pour les applications d’IA dans les ordinateurs et les smartphones. La puce d’IBM est développée dans le complexe Albany NanoTech d’IBM et a été présentée dans un article publié par IBM Research. « Nous ne sommes qu’au début d’une révolution de l’IA qui va redéfinir notre mode de vie et de travail. En particulier, les DNN ont révolutionné le domaine de l’IA et gagnent de plus en plus en importance avec l’avènement des modèles de fondation et de l’IA générative. Mais l’exécution de ces modèles sur des architectures informatiques numériques traditionnelles limite leurs performances et leur efficacité énergétique », déclare IBM.
Des progrès ont été réalisés dans le développement de matériel spécifiquement destiné à l’inférence de l’IA, mais bon nombre de ces architectures séparent physiquement la mémoire et les unités de traitement. Cela signifie que les modèles d’IA sont généralement stockés dans un emplacement de mémoire discret et que les tâches de calcul nécessitent un brassage constant des données entre la mémoire et les unités de traitement. Ce processus ralentit les calculs et limite l’efficacité énergétique maximale réalisable.
IBM Research a étudié les moyens de réinventer la manière dont l’IA est calculée. L’informatique analogique en mémoire, ou plus simplement l’IA analogique, est une approche prometteuse qui permet de relever le défi en empruntant des caractéristiques clés du fonctionnement des réseaux neuronaux dans les cerveaux biologiques. Dans notre cerveau et celui de nombreux autres animaux, la force des synapses (qui sont les “poids” dans ce cas) détermine la communication entre les neurones.
Pour les systèmes d’IA analogiques, nous stockons ces poids synaptiques localement dans les valeurs de conductance des dispositifs de mémoire résistive à l’échelle nanométrique, tels que la mémoire à changement de phase (PCM) et effectuer des opérations de multiplication-accumulation (MAC), l’opération de calcul dominante dans les DNN, en exploitant les lois du circuit et en atténuant la nécessité d’envoyer constamment des données entre la mémoire et le processeur.
Mémoire à changement de phase
La Mémoire à changement de phase fonctionne lorsqu’une impulsion électrique est appliquée à un matériau, ce qui modifie la conductance du dispositif. Le matériau passe d’une phase amorphe à une phase cristalline : une impulsion électrique plus faible rendra le dispositif plus cristallin, offrant moins de résistance, tandis qu’une impulsion électrique plus forte rendra le dispositif plus amorphe, offrant plus de résistance.
Au lieu d’enregistrer les 0 et les 1 habituels des systèmes numériques, le dispositif PCM enregistre son état sous la forme d’un continuum de valeurs entre l’état amorphe et l’état cristallin. Cette valeur est appelée poids synaptique et peut être stockée dans la configuration atomique physique de chaque PCM. La mémoire est non volatile, de sorte que les poids sont conservés lorsque l’alimentation électrique est coupée.
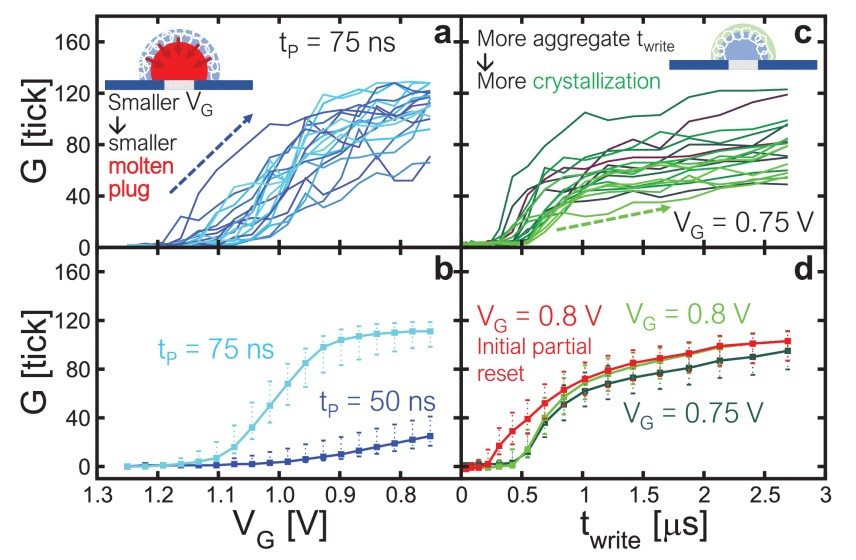
Trajectoires de conductance pour les dispositifs PCM à partir d’une réinitialisation profonde initiale, pour (a) une tension de grille décroissante VG et (c) une twrite totale croissante (agrégation de plusieurs impulsions de programmation tP ). (b) Évolution médiane, ±1σ sur 512×512 dispositifs. (d) Impact du démarrage à partir d’un état de RESET partiel plutôt que d’un état de RESET profond.
Le PCM fonctionne lorsqu’une impulsion électrique est appliquée à un matériau, ce qui modifie la conductance du dispositif. Le matériau passe d’une phase amorphe à une phase cristalline : une impulsion électrique plus faible rendra le dispositif plus cristallin, offrant moins de résistance, tandis qu’une impulsion électrique plus forte rendra le dispositif plus amorphe, offrant plus de résistance. Au lieu d’enregistrer les 0 et les 1 habituels des systèmes numériques, le dispositif PCM enregistre son état sous la forme d’un continuum de valeurs entre l’état amorphe et l’état cristallin. Cette valeur est appelée poids synaptique et peut être stockée dans la configuration atomique physique de chaque PCM. La mémoire est non volatile, de sorte que les poids sont conservés lorsque l’alimentation électrique est coupée.
Une puce d’IA analogique à signaux mixtes qui rivalise avec les systèmes numériques
Pour que le concept d’IA analogique devienne réalité, deux défis majeurs doivent être relevés : ces matrices de mémoire doivent être capables de calculer avec un niveau de précision équivalent à celui des systèmes numériques existants, et elles doivent pouvoir s’interfacer de manière transparente avec d’autres unités de calcul numériques, ainsi qu’avec un tissu de communication numérique sur la puce d’IA analogique.
Dans un article publié aujourd’hui dans Nature Electronics, IBM Research a fait un grand pas en avant pour relever ces défis en introduisant une puce d’IA analogique à signaux mixtes de pointe pour l’exécution de diverses tâches d’inférence DNN. Il s’agit de la première puce analogique qui a été testée pour être aussi performante dans les tâches d’IA de vision par ordinateur que ses homologues numériques, tout en étant considérablement plus économe en énergie.
La puce a été fabriquée dans le complexe NanoTech d’Albany d’IBM et se compose de 64 noyaux de calcul analogiques en mémoire (ou tuiles), chacun contenant un réseau de cellules d’unités synaptiques de 256 par 256. Des convertisseurs analogiques-numériques compacts, basés sur le temps, sont intégrés dans chaque tuile pour assurer la transition entre les mondes analogique et numérique. Chaque tuile est également dotée d’unités de traitement numérique légères qui exécutent des fonctions d’activation neuronale non linéaires simples et des opérations de mise à l’échelle.
Précision et efficacité du calcul en mémoire analogique pour les réseaux neuronaux profonds
Chaque tuile peut effectuer les calculs associés à une couche d’un modèle DNN. Les poids synaptiques sont codés sous forme de valeurs de conductance analogiques des dispositifs PCM. Une unité de traitement numérique globale est intégrée au milieu de la puce. Elle met en œuvre des opérations plus complexes qui sont essentielles pour l’exécution de certains types de réseaux neuronaux. La puce dispose également de voies de communication numériques au niveau des interconnexions de toutes les tuiles et de l’unité de traitement numérique globale.
En utilisant la puce, nous avons réalisé l’étude la plus complète sur la précision de calcul de l’informatique analogique en mémoire et avons démontré une précision de 92,81 % sur l’ensemble de données d’images CIFAR-10. Nous pensons qu’il s’agit du niveau de précision le plus élevé de toutes les puces actuellement rapportées utilisant une technologie similaire. Dans cet article, nous avons également montré comment nous pouvions combiner de manière transparente le calcul analogique en mémoire avec plusieurs unités de traitement numérique et un tissu de communication numérique.
Le débit mesuré par zone pour les giga-opérations par seconde (GOPS) par zone est une mesure standard pour décrire l’efficacité du calcul où les opérations de calcul brutes sont normalisées par une zone de calcul concomitante. Les multiplications matricielles entrée-sortie 8 bits de 400 GOPS/mm2 de la puce sont plus de 15 fois supérieures aux précédentes puces de calcul multicœur en mémoire basées sur la mémoire résistive, tout en atteignant une efficacité énergétique comparable.
Les giga-opérations par seconde (GOPS) par zone sont une mesure standard pour décrire l’efficacité du calcul où les opérations de calcul brutes sont normalisées par une zone de calcul concomitante. Elle montre essentiellement qu’il y a plus d’opérations pour une surface donnée, ce qui signifie que cette puce est un moteur de calcul plus efficace.
Architecture de l’accélérateur d’IA analogique à signaux mixtes
En combinant les convertisseurs analogique-numérique (ADC) efficaces en termes de surface et d’énergie, le calcul multiplicateur-accumulateur hautement linéaire et les blocs de calcul numérique de cette puce à 64 carreaux avec le transport de données massivement parallèle que nous avons montré dans une puce à 34 carreaux présentée au symposium IEEE VLSI en 2021, nous avons maintenant démontré un grand nombre des éléments constitutifs nécessaires pour réaliser une vision architecturale pour une puce d’accélérateur d’inférence d’IA analogique rapide et à faible consommation.
- Puce d’inférence de 14 nm d’IBM et micrographie ;
- Puce d’inférence de 14 nm d’IBM et micrographie ;
- Les blocs fonctionnels comprennent l’entrée LP, la sortie LP, les tuiles PCM. Le transport de la durée entre les tuiles à l’aide d’un maillage de signaux parallèles à deux dimensions est également illustré ;
- Les CDF des erreurs de bits montrent un transport de durée très précis à travers la puce pour des distances de déplacement allant jusqu’à six tuiles ;
- Image au microscope électronique à transmission d’un dispositif PCM intégré dans une partie arrière de 14 nm ;
- Chaque poids DNN est codé à l’aide de quatre dispositifs PCM ;
- La lecture/écriture par rangée (à gauche) pendant la programmation utilise les mêmes chemins de circuit (et les non-idéalités associées) que pendant l’inférence complète (à droite) ;
- Le circuit de lecture de l’amplificateur de détection d’un seul dispositif (“backdoor”) peut mesurer la conductance du dispositif en Μs ;
- Les mesures utilisant les modes décrits en (g) et (h) sont bien corrélées.
Grâce à notre apprentissage, nous avons conçu une architecture d’accélérateur comme celle-ci, qui a été publiée plus tôt cette année dans IEEE Transactions on VLSI systems. Notre vision combine de nombreuses tuiles de calcul analogiques en mémoire avec un mélange de cœurs de calcul numériques à usage spécifique connectés à un maillage 2D massivement parallèle. En conjonction avec la formation sophistiquée basée sur le matériel que nous avons développé ces dernières années, nous prévoyons que ces accélérateurs fourniront des précisions de réseau neuronal équivalentes à celles des logiciels pour une grande variété de modèles dans les années à venir.
La puce d’IBM combine le calcul analogique et numérique pour accélérer l’IA
Le calcul analogique en mémoire (AIMC) avec des dispositifs de mémoire résistive pourrait réduire la latence et la consommation d’énergie des tâches d’inférence des réseaux neuronaux profonds en effectuant directement des calculs dans la mémoire. Toutefois, pour obtenir des améliorations de bout en bout en matière de latence et de consommation d’énergie, l’AIMC doit être combiné à des opérations numériques et à des communications sur la puce.
L’IA analogique d’IBM face au cerveau humain : innovation ou tromperie ?
La puce d’IA analogique d’IBM est un prototype prometteur qui vise à réduire la latence et la consommation d’énergie des tâches d’inférence des réseaux neuronaux profonds en effectuant directement des calculs dans la mémoire. Toutefois, cette puce ne serait pas encore prête à remplacer les puces numériques actuelles, car elle présente des limites en termes de précision, de fiabilité, de flexibilité et d’évolutivité. De plus, elle soulève des enjeux éthiques et sociétaux sur l’utilisation et le contrôle de l’IA analogique, qui imite le fonctionnement du cerveau humain. Il faudra donc encore beaucoup de recherche et de développement pour faire de cette puce une solution viable et responsable pour l’IA du futur.
Pour certains analystes, dire que IBM dévoile une puce d’IA analogique qui fonctionne comme un cerveau humain serait à la fois intrigant et trompeur. Car cela suggère que la puce d’IBM est capable de reproduire les fonctions cognitives et les processus neuronaux du cerveau humain, ce qui n’est pas le cas. La puce d’IBM serait en fait un accélérateur d’intelligence artificielle qui utilise des techniques de calcul analogique en mémoire pour exécuter des réseaux de neurones profonds (DNN) avec une efficacité et une précision élevées. Ces DNN sont des modèles mathématiques inspirés par le fonctionnement des neurones biologiques, mais ils ne sont pas équivalents au cerveau humain. La puce d’IBM serait donc une innovation technologique importante, mais elle ne fonctionne pas comme un cerveau humain.